



Data annotators face critical challenges when machine learning models struggle with accuracy and reliability due to poorly structured training data. Companies developing solutions like autonomous vehicles and healthcare diagnostics particularly feel this pain, as their AI systems cannot perform optimally without high-quality annotated datasets.
To address these challenges, the industry is adopting automated annotation tools, synthetic data generation, and improved edge case handling techniques. Additionally, organizations are implementing ethical AI practices to ensure responsible data collection and labeling, addressing concerns about bias and fairness in model training.
This transformation in data annotation practices enables businesses to develop more reliable AI systems that can handle complex tasks across industries, from visual object recognition to natural language processing.
However, success in implementing data annotation solutions requires staying informed about these evolving annotation trends and applying them based on specific use cases and requirements. As the field continues to advance, organizations that adapt to these changes will be better positioned to develop AI models that meet both technical and ethical standards.
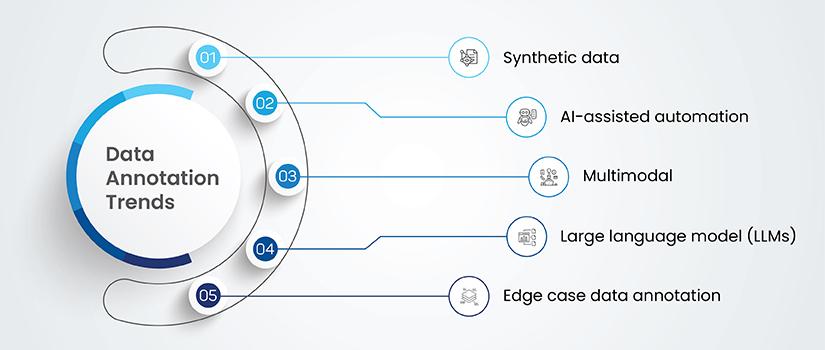
Top 5 Data Annotation Trends to Watch Out
As computer vision continues to evolve, the role of data annotation and labeling is becoming more sophisticated, shaping the accuracy and efficiency of AI-driven applications. In 2025, advancements in automation, AI-assisted labeling, and quality control will redefine how training data is prepared using data annotation tools and computer vision annotation tools.
From the increasing adoption of synthetic data to the integration of types of data annotation and data annotation techniques, these trends will optimize annotation workflows, reduce costs and enhance model performance. Below, we explore five key trends that will influence the future of data annotation for computer vision.
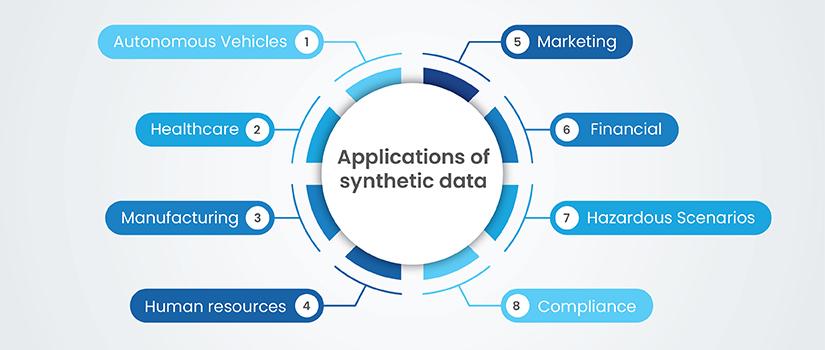
Synthetic Data
Synthetic data refers to datasets that are artificially created using simulations, algorithms, or advanced modeling methods. Unlike traditional data collected from real-world scenarios, synthetic data is purposefully designed to mimic real-world conditions or even generate entirely new situations.
Generated through advanced techniques like generative adversarial networks (GANs), 3D modeling, and procedural algorithms, synthetic data allows researchers to create vast, diverse, and highly controlled datasets tailored to specific AI training requirements.
Advantages of Synthetic Data
1. Cost-Effectiveness – Synthetic data eliminates the need for expensive fieldwork, specialized equipment, and manual annotation by generating datasets in virtual environments, significantly lowering costs.
2. Privacy Compliance – As artificial data, synthetic datasets bypass privacy concerns associated with regulations like GDPR and HIPAA, making them ideal for sensitive fields like healthcare and finance.
3. Bias Reduction – By allowing controlled generation of balanced and diverse datasets, synthetic data reduces biases present in real-world data, leading to fairer AI outcomes.
AI-assisted Automation and Human Oversight
The hybrid combination of AI-assisted automation and human oversight is growing exponentially. This approach leverages the speed and scalability of automation while retaining human expertise for tasks requiring nuanced understanding or critical quality control.
Automation with human oversight refers to using AI-powered annotation tools to handle repetitive and labor-intensive tasks, such as drawing bounding boxes or segmenting images. Humans, however, remain involved to validate outputs, address complex edge cases, and ensure the final dataset meets the highest quality standards.
Advantages of Automation with Human Oversight
- Faster Annotation Process – AI-assisted tools can handle large volumes of data at unprecedented speeds, significantly reducing the time required for annotation.
- Cost-Effective Solution – By automating repetitive tasks, businesses save on labor costs while maintaining quality through human validation.
- High Data Quality – Human reviewers validate automated outputs, ensuring the final datasets are free from errors and meet accuracy standards.
Multimodal Annotation
Multimodal annotation involves labeling and associating data across multiple sensory modalities, such as images, videos, text, audio, and sensor data. This approach enhances the depth and contextual understanding of visual data by integrating additional information beyond just pixels. Multimodal annotation is crucial in applications like autonomous driving, robotics, medical imaging, and smart surveillance. It allows AI to comprehend real-world scenarios more effectively by correlating visual cues with textual descriptions, audio signals, or even spatial data.

Advantages of Multimodal Annotation in Computer Vision
- Model Accuracy – By incorporating multiple data sources, models develop a richer understanding of objects, scenes, and interactions, leading to improved performance in object detection, segmentation, and recognition.
- Contextual Understanding – Helps AI interpret ambiguous or unclear visual data by linking it with other sensory inputs, reducing errors in perception and decision-making.
- Enhanced AI Generalization – AI models trained on multimodal data perform better across varied real-world scenarios since they rely on diverse inputs rather than a single data type.
- Optimized Performance – Autonomous vehicles, medical AI, and robotics benefit from multimodal annotation, enabling better situational awareness and decision-making capabilities.
Data Annotation for LLMs in Computer Vision
Large Language Models (LLMs) are increasingly being integrated into computer vision applications, enabling models to interpret and generate text alongside visual data. The fusion of LLMs with computer vision has given rise to Vision-Language Models (VLMs) such as OpenAI’s GPT-4V, Google’s Gemini, and Meta’s LLaVA, which require specialized data annotation to train effectively.
Advantages of Data Annotation for LLMs in Computer Vision
- Contextual Understanding – Enables AI to comprehend images with deeper contextual reasoning rather than just object detection.
- Zero-Shot and Few-Shot Learning – Well-annotated datasets allow LLM-powered vision models to generalize better across new images without extensive retraining.
- Accurate Image-Text Generation –Helps AI generate coherent and detailed descriptions of images, which is essential for accessibility applications like screen readers for the visually impaired.
- AI-Human Interaction – Data annotation tailored for dialogue-based image understanding improves chatbot responses in applications such as virtual assistants, e-commerce, and education.
- Stronger Performance in Complex Vision Tasks – Enables fine-grained reasoning, object relationships, and multimodal decision-making, crucial for domains like medical imaging, robotics, and autonomous systems.
Edge Case Data Annotation
As computer vision data labeling advances, edge case data annotation is crucial for handling rare, complex scenarios like unusual lighting, occlusions, or rare traffic events in autonomous driving. Traditional datasets often lack these anomalies, leading to AI failures in unpredictable conditions. Prioritizing edge case annotation enhances model robustness, ensuring reliable performance in self-driving cars, medical imaging, and security surveillance, where misclassifications can have serious consequences.
Advantages of Edge Case Data Annotation
- Boosts Accuracy in Challenging Scenarios – AI trained on diverse edge cases can confidently handle rare and high-risk situations, improving performance where it matters most.
- Reduces Critical Errors – Addressing edge cases in training helps prevent costly or dangerous mistakes, whether in traffic navigation, medical diagnostics, or security surveillance.
- Enhances Generalization Across Conditions – AI models trained on edge cases become more adaptable, learning to function across a broader range of environments, lighting conditions, and unexpected inputs.

Conclusion
Businesses can gain a competitive advantage in building high-performing AI solutions by staying current with evolving data annotation capabilities. The computer vision landscape now offers AI-assisted labeling, automation and advanced annotation techniques that enhance accuracy and efficiency.
This integration of smarter workflows and new annotation approaches leads to better-performing AI models. While quality data remains fundamental, the true value comes from how effectively that data is annotated – a key factor shaping AI’s future development and applications.












